
12. July 2022 By Attila Papp
Building a secure data lake with AWS Lake formation
Introduction
Without a doubt, most companies with different pieces of information scattered around their organization would benefit from having a data lake. No wonder data lakes have been popping up at companies looking to improve their analytics further.
I was honored to work on an exciting data lake project and decided to write a blog post about my experience with AWS Lake formation. In this blog post, we will explore what data lakes are, what’s the difference compared to data warehouses, and then take a detailed look at Lake formation. It is aimed at technical audiences who are new to Lake formation and want to understand its story conceptually.
What is a data lake?
Simply put: an extensive collection of structured, unstructured data with a flexible format and preprocessing for querying – or in other words, various types of data stored in one place to bring down data silos and make sense of the bigger picture. Data lakes were initially built with Apache Hadoop clusters on-premises; however, nowadays, they are in the cloud. Cloud swiftly took over this technology area because it can infinitely scale storage and computing resources if needed – while providing flexible pricing.
Data in a data lake needs to be shareable yet securely handled; boundless yet efficient. Lake formation is an excellent service for setting up a secure, efficient, and shareable data lake.
Data lakes vs. data warehouses
When I started on my current project, I initially had the following question lingering in my head: I understand the need for bringing down data silos, but didn’t we already have the technology for it 30-40 years ago with data warehouses?
As it turns out, data lakes are more than just a rebranding and migrating an old approach to the cloud. First, traditionally, a data warehouse only handles relational data, whereas a data lake hosts all kinds of data. They can be structured, semi-structured (like JSON), or unstructured (like pictures). They also differ in how storage and computation are intertwined: with a data warehouse, storage usually is closely combined with computation, and products handle these together. However, with a data lake, storage is detached from computation: data could be processed with all types of computational approaches.
A data lake is much more flexible than a traditional data warehouse as it doesn’t necessarily need meticulous cleaning, preprocessing, or transformation to prepare the data. Instead, data might be stored and provided in a raw, original state.
It is also vital to emphasize that even though data lakes are an evolution of data warehouses, they might not replace them in every case. I recommend this well-written article to learn more about the differences and whys.
The architecture of a serverless data lake
The movement of data in a data lake can be understood by comparing it to pipelines. We ingest, store, process, and report the data in a data pipeline. AWS offers several solutions for each step of the data pipeline.
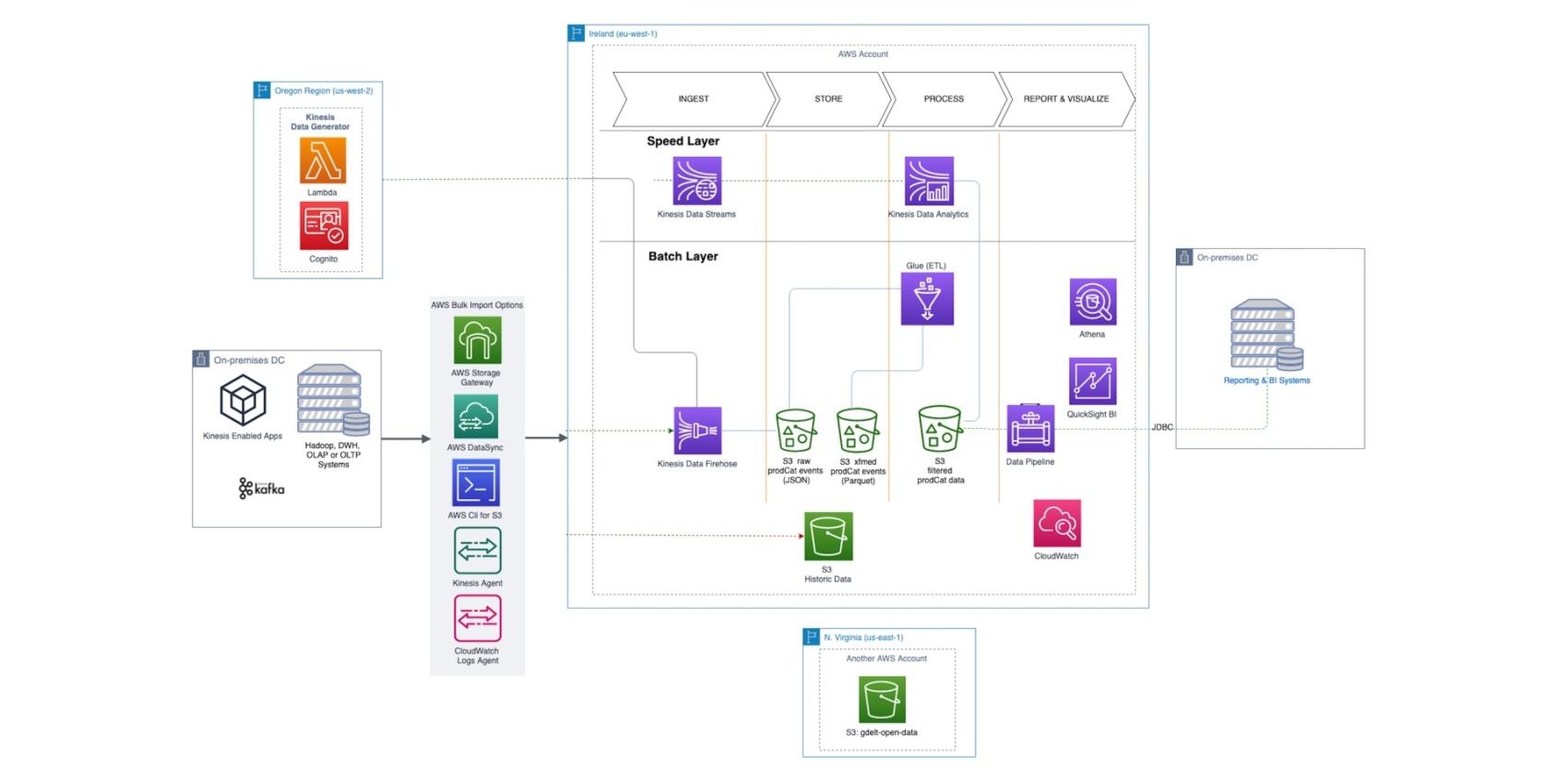
Source: https://catalog.us-east-1.prod.workshops.aws/workshops/ea7ddf16-5e0a-4ec7-b54e-5cadf3028b78/en-US/introduction
The essential components for a serverless data pipeline are ingestion (e. g. Lambda) to get data from other systems. As storage, S3 is perfect for data lakes due to its impressive durability, price, and elasticity. In some cases, the data stored on S3 is queried in a raw format; in other cases, it needs to be preprocessed before querying – this is done with Glue Jobs. Either way, we can write queries using Athena, which uses the Glue Catalog to understand the metadata of what we have. The Glue Catalog’s metadata is populated using Glue Crawlers.
Lake formation offers an additional layer on top of all this. In the next section, we will explore its features in detail and provide examples for some of the use cases.
Lake formation features
As mentioned earlier, Lake formation is a managed service under the umbrella of AWS’ big data solutions. It is a crucial solution to make a data lake secure, shareable (and perhaps efficient). It provides an additional layer of management and governance on top of what is achievable with Glue and S3. It can also offer blueprints for faster data ingestion and handling. In addition, data lake access can be federated to external users.
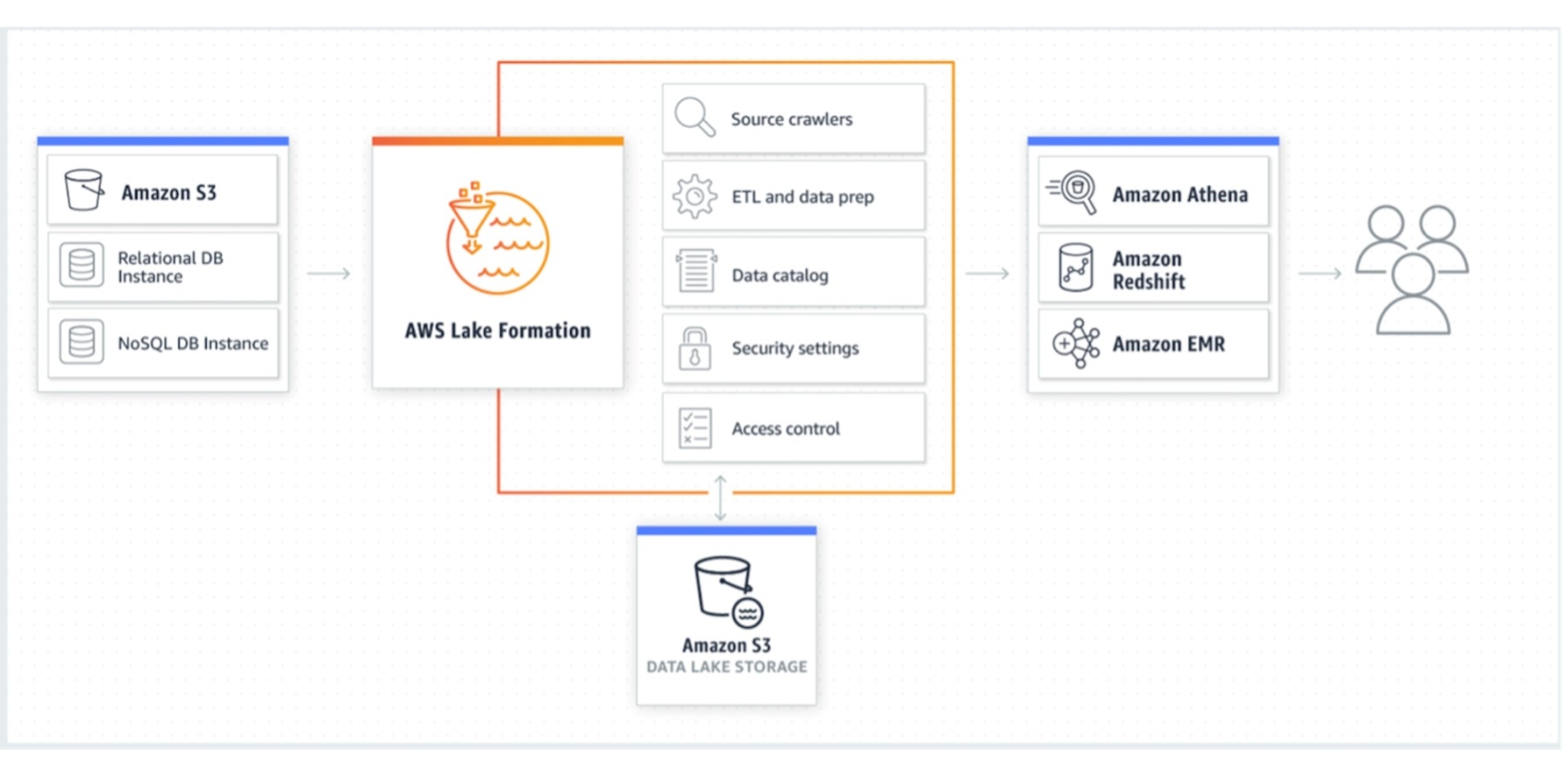
Source: https://aws.amazon.com/lake-formation/
AWS understood the need to make it easy to start a data lake. Lake formation has several features for new and mature data lakes. Blueprints and workflows make it easy to get started, while access control and governed tables are something experienced users sought after.
Blueprints
A blueprint serves as a data management template, making it easier to get data into the data lake. Lake formation offers blueprints for various sources, e. g.: relational databases, CloudTrail logs, etc. A workflow can be created from a blueprint, essentially a data pipeline consisting of Glue crawlers, jobs, and triggers that orchestrate the loading and update of data. Blueprints get data source, target, and schedule as input and configure the workflow.
Workflow
A workflow is a set of Glue resources consisting of jobs, crawlers, and triggers. A workflow created in Lake formation orchestrates and tracks the status of these components located in Glue. When creating a workflow, we define what blueprint it is based on – and a workflow is run on-demand or on a schedule.
Access control
Lake formation offers a diverse set of capabilities when it comes to access control.
Tag-based access control (TBAC) is an approach to defining authorization based on attributes – in Lake formation, these attributes are called LF-tags. You can attach LF-tags to any data catalog resource, Lake formation principals, tables, and columns. Then, assign and revoke permissions in Lake formation using these LF-tags. Lake Formation allows operations on those resources when the principal’s tag matches the resource tag. TBAC is helpful in growing fast environments where policy management would not suffice.
Row-level access control is a simple and performant solution to securing tables regarding data sharing – it exactly does what its name suggests. In addition, Lake Formation also provides centralized auditing and compliance reporting.
Lake formation has even more capable data filtering options. For example, with the help of column-level security (column filtering), data lake administrators can specify which columns should be included for which users. This can help avoid sharing personally identifiable information (PII), such as birthdate.
Combine these two, and you can have cell-level security, where columns could be hidden/shown based on their values for specific users based on specific criteria. Pretty impressive!
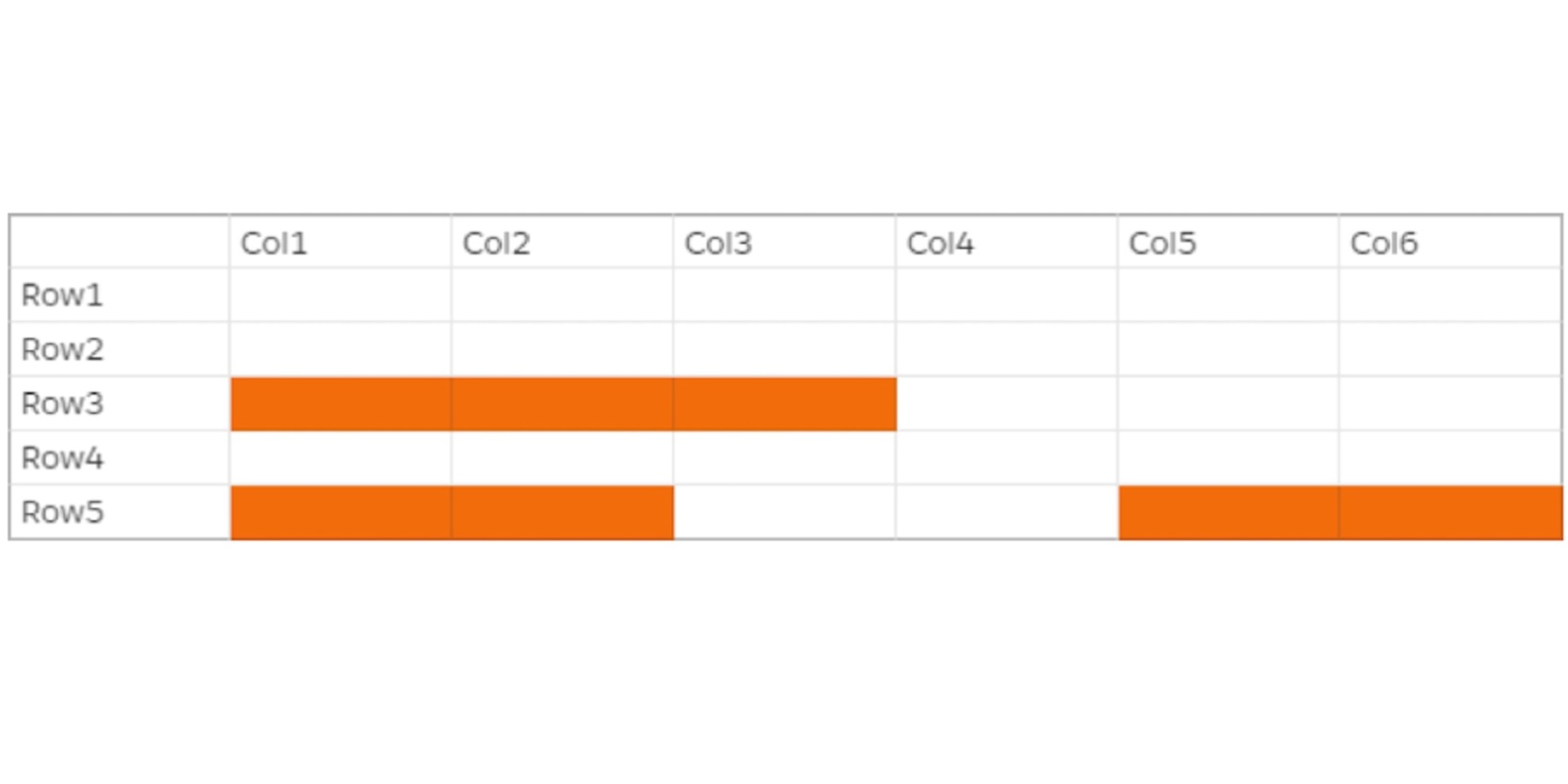
Source: https://docs.aws.amazon.com/lake-formation/latest/dg/lake-formation-dg.pdf
Governed tables
Lake Formation uses governed tables to support atomic, consistent, isolated, and durable (ACID) transactions. It is helpful in use cases where multiple users concurrently insert, delete, and modify governed tables in a data lake. On top of this, Lake Formation automatically compacts and optimizes files in the background to improve query performance.
Shortcomings
Spotty CloudFormation support
As of July 2022, some crucial parts are unavailable in CloudFormation/CDK. Some are not even available through an API, so you have to use the web GUI for some of the resources to configure a proper Lake Formation stack. I am not joking!
An example of this: Data location permissions are supported neither in Cloud Formation nor through the API. So, if you have Glue crawlers working with a database that Lake Formation governs, you must manually configure these permissions through the GUI – which is a common use case. Manually adding 25+ permissions on the GUI for each crawler is not fun.
Data location permissions and row-level filtering are not available in CloudFormation/CDK today.
Migration to a Lake Formation permission model is cumbersome for established data lakes
After you set up Lake Formation, there is still a possibility to manage databases and tables through regular IAM. This is done by assigning the principal IAMAllowedPrincipals to the given resource in Lake Formation, so it knows which resources it should ignore. A lengthy article describes the differences between the two permission models. Still, the migration is all about getting rid of IAMAllowedPrincipals and setting up equal permissions in Lake Formation as previously in IAM. And here comes the first drawback: there is no easy way to batch remove IAMAllowedPrincipals. So, if you want to do batch migrations, you will have to write a script – which feels unnecessary.
I feel AWS could do better on this front to make the permission model migration a bit more convenient somehow.
Summary
This blog post explored what data lakes are and how they differ from traditional data warehouses. Finally, we took a detailed look at Lake Formation understanding its feature, strengths, and weaknesses.
As with many novel innovations, the road to an ideal target state is sometimes a bit rocky. However, as long as the end seems correct, it is okay. This is how I feel about Lake Formation: it provides some astonishing capabilities even today, and judging by its recent development, they are on an excellent track, but it is not mature yet. I would advise using it in production if there is a clear need for fine-grained access control.
Let me know in the comments or over e-mail what you think! Thanks for reading.

Category: |
|
Tags: |
Amazon Web Services (AWS) Cloud Big Data Architecture Data Lake |

