
7. June 2022 By Kristóf Bencze
Machine Learning Operations in Apache Airflow
During one of our projects, we helped a customer optimize their customer experience processes by introducing machine learning models for the classification of incoming customer support emails and a chatbot for 24/7 available support. Since these ML models were the first production-grade AI applications for this customer, there was a need not just for the ML models but for machine learning infrastructure too. The most important characteristics required from this infrastructure were the maintainability, observability, and easy enrichment of models with new features while providing an easy way for automated deployment and rapid machine learning model development cycles. To fulfill these needs, we introduced machine learning operations for this customer with the Airflow framework during this project.
ML Ops
Machine learning operations aim to unify and automate the whole lifecycle of a machine learning model, including the data acquisition, feature engineering, the model development, -validation, -deployment, -monitoring, and retraining, the rapid and automated testing of models, the introduction of new data sources and features while providing an easy, automated way for serving, monitoring, and validating machine learning models.
1.2 Airflow:
Airbnb initially developed Apache Airflow to manage the company's increasingly more complex workflows for data engineering pipelines. The platform takes care of authoring, scheduling, monitoring, and alerting workflows while taking care of connections to external systems such as databases, cloud services, Hadoop, etc. In airflow, tasks are written in python, and they are organized into Directed Acyclic Graphs (DAGs), where the relationships and dependencies between tasks are defined. The most popular use case for Airflow is ETL pipelines, automated reporting, automated backups, and Machine Learning Operations. In this article, we are aiming to explore the latter use case.
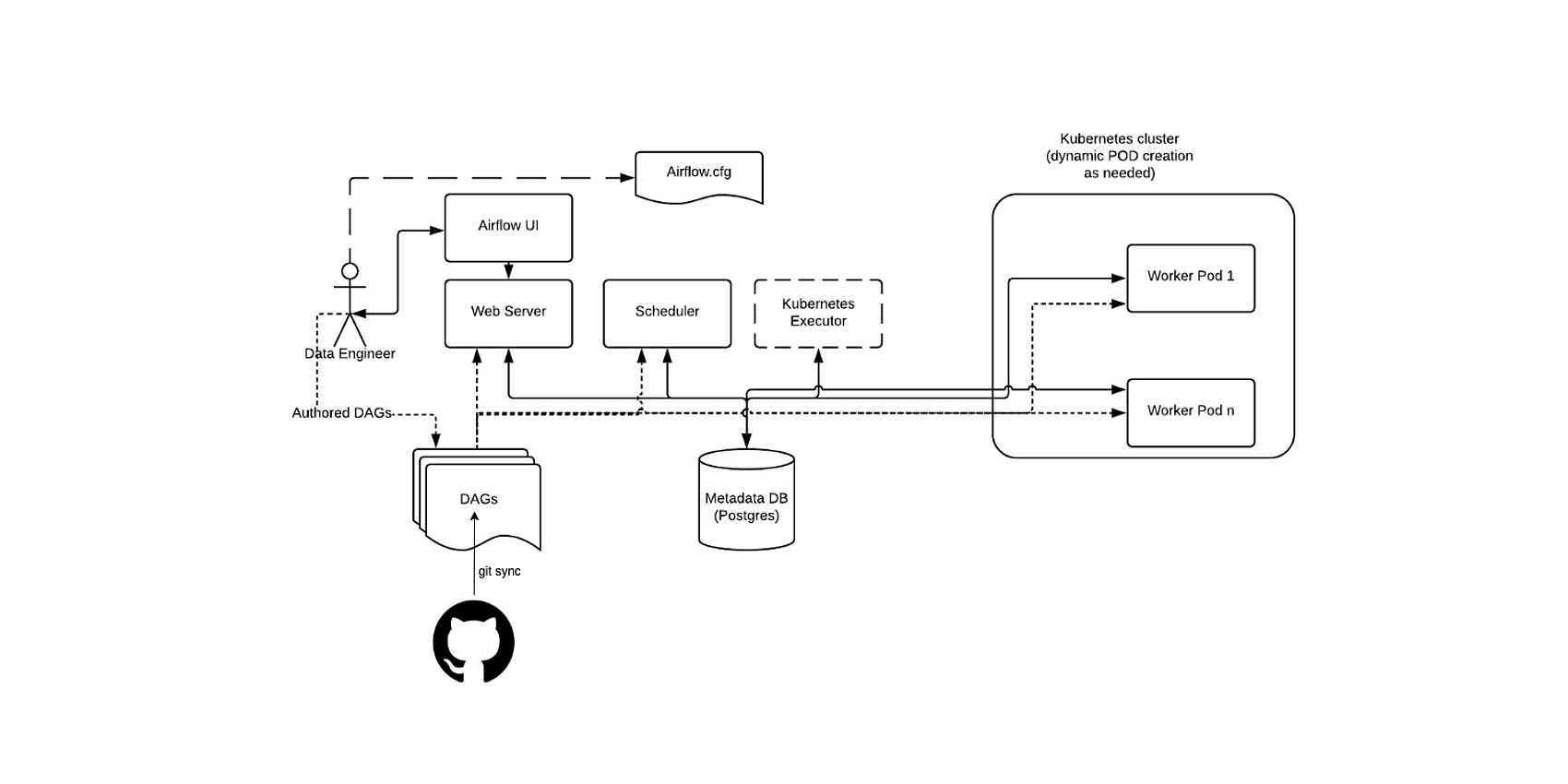
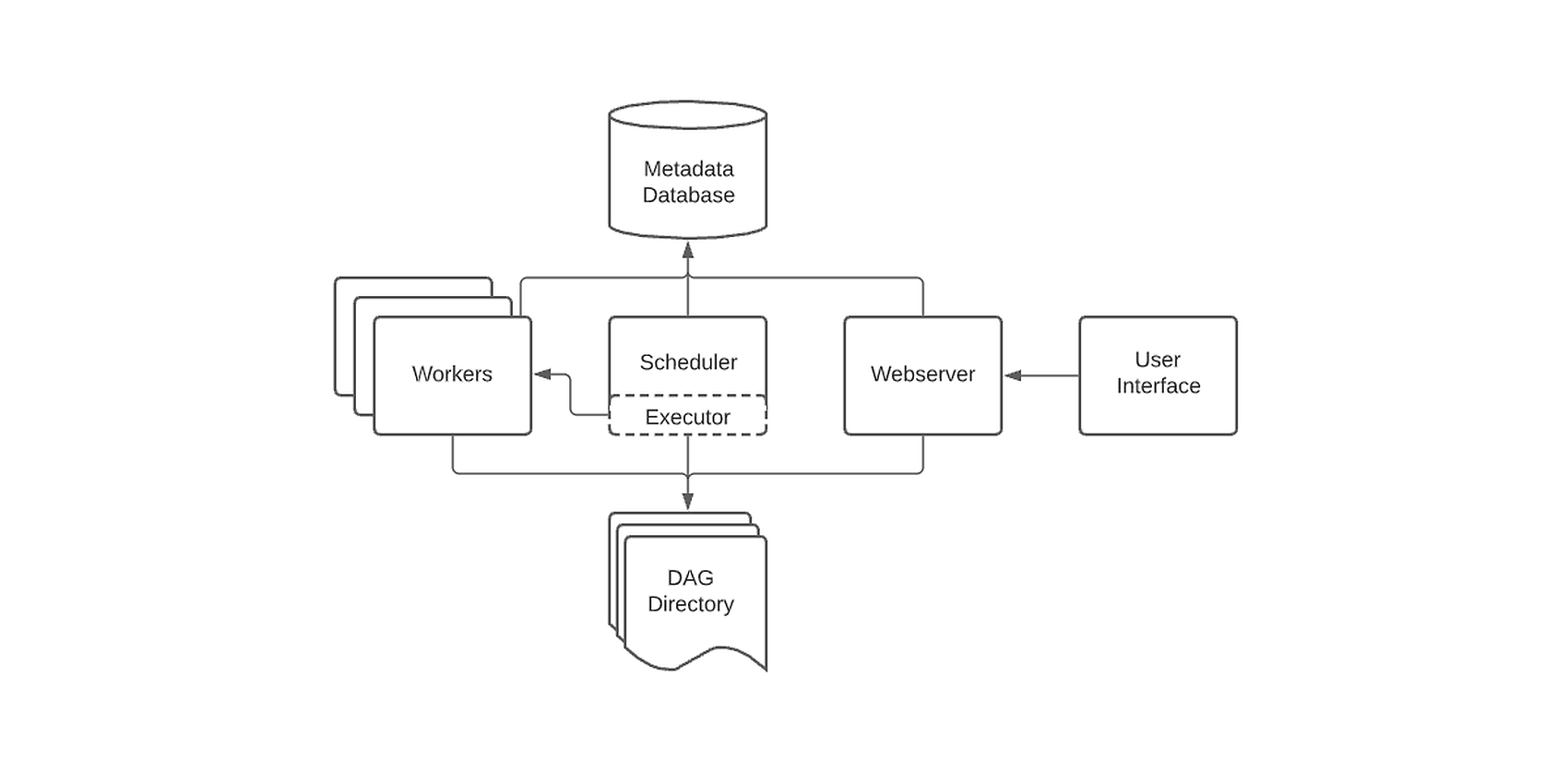
Airflow based architecture
The airflow platform beside the DAGs consists of 4 main parts: scheduler, executor, web server, and metadata database. The scheduler is responsible for triggering the scheduled workflows and submitting the tasks to the executor. The executor handles the running of the functions, which can be done locally and remotely. The production-grade executors never run tasks locally; they always delegate the execution of the tasks to a worker node or a Kubernetes job, depending on the executor type. The web server provides the user interface for data engineers and scientists to trigger and observe the behavior of tasks and DAGs. The last component is a metadata database used by all other components to store state; multiple database engines are used for this purpose, most commonly PostgreSQL.
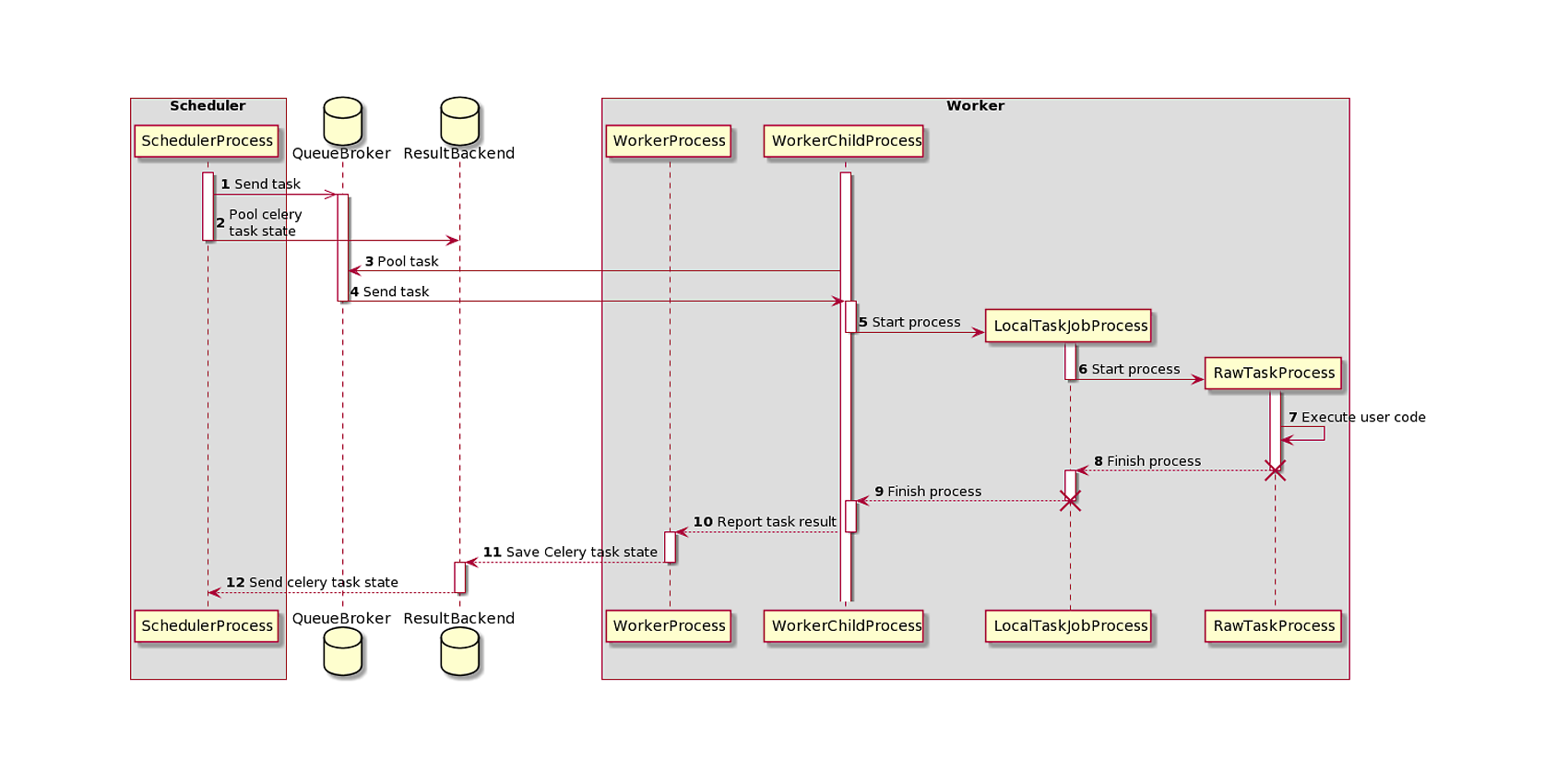
Celery Executor architecture
The most widely used airflow executor is the Celery executor, consisting of three components: a message broker (usually Redis), a result backend, and the worker nodes. It handles the delegation of the tasks in the following way: upon the triggering of a DAG, the scheduler pushes the tasks of the DAG to the message broker and the status to the result backend. From the message queue, the worker nodes consume the task, execute it, and update the result backend with the result of the task's execution. An important drawback of the celery executor is that it doesn't allow dynamic resource allocation; it works with a fixed number of workers, which means we would end up with an overprovisioned or under-provisioned airflow cluster.
Actual Airflow Setup:
Instead of the commonly used Celery executor, we chose a bit later released Kubernetes executor. Rather than using workers and message brokers, the Kubernetes executor offloads the scheduling to a Kubernetes cluster which launches a Kubernetes job for each task. This way, every task runs in a new pod, and these pods are stopped as soon as the task is finished. Therefore, the Kubernetes executor introduces much more elasticity than the other executors allowing the dynamic shrinking and scaling of the cluster. Furthermore, every task runs in a different pod, which will enable us to use specific images for every various task. This allows data engineers and scientists to avoid dependency hell when introducing new python libraries. Another benefit of the Kubernetes executor is that it improves the fault tolerance since, in this setup a failing task won't crash an entire worker node which is the case with celery.
Airflow setup with Kubernetes executor and git-sync sidecar container
There are multiple ways to inject the DAG files into airflow: mounting a persistent volume to the airflow components that were previously populated, baking the DAG files into the docker images of airflow, and using a git-sync sidecar container. We consider the last option the only go-to method for production-grade pipelines since DAGs are an integral part of our production pipelines. That's why they must be version controlled. In addition, this solution is a lot more flexible from a DevOps perspective since it's on a higher level of automation because an introduction of a new DAG can be completed with a simple merge request and a commit instead of tedious docker file creations and uploads to a persistent volume.
Complete ML Ops architecture
When designing a complete ML Ops architecture, the most crucial goal is to create a system that handles all aspects of machine learning development and deployment lifecycle in an automated manner. Therefore, the architecture was designed to fulfill the needs mentioned above. It consists of three essential parts: the production Kubernetes cluster, which hosts the machine learning model as a web service for the outside world, the development cluster in which the airflow is hosted in the setup detailed above, and the data lake, where all the training data resides. This article doesn't describe the data lake's setup because it can vary from a data warehouse through an object store like Amazon S3 to a cloud-native spark cluster.
The actual model development and training take place inside a DAG in airflow, where all distinct steps of a machine learning pipeline are added as separate tasks. Data collection is an essential part of every ML pipeline; it was excluded from the architecture; we took for granted that all the necessary raw data is available in our data lake. As a first step, the raw data needs to be subjected to data validation/data quality tests which act like unit tests on the data. This needs to be done to mitigate any defects based on data errors because if those errors are not caught in the early stages, they will add up over time. The next task after data validation is data preparation, where data gets cleaned, and features are extracted with normalization, labeling and dimension reduction to get the data training ready. Model training is the most critical task of this pipeline, where we try to fit a loss function on training data to get the best combination of weights and bias, which we call a machine learning model. Once the model is ready, it needs to be evaluated with validation data because evaluation with training data would lead to overfitting. Evaluation usually happens with cross-validation, which helps to assess the model's performance and tune hyperparameters. After the evaluation phase, we got the model with the optimal hyperparameters; the performance of this model needs to be measured too. Finally, a separate test data set needs to be used for validation, which took part neither in training nor in the hyperparameter tuning. This data set must have a similar probabilistic distribution to the training set so bias can be eliminated, and the real performance of the model measured. Depending on the validation result, the machine learning model can be added to the product model registry or discarded to the development registry, which will be deleted after a retention period.
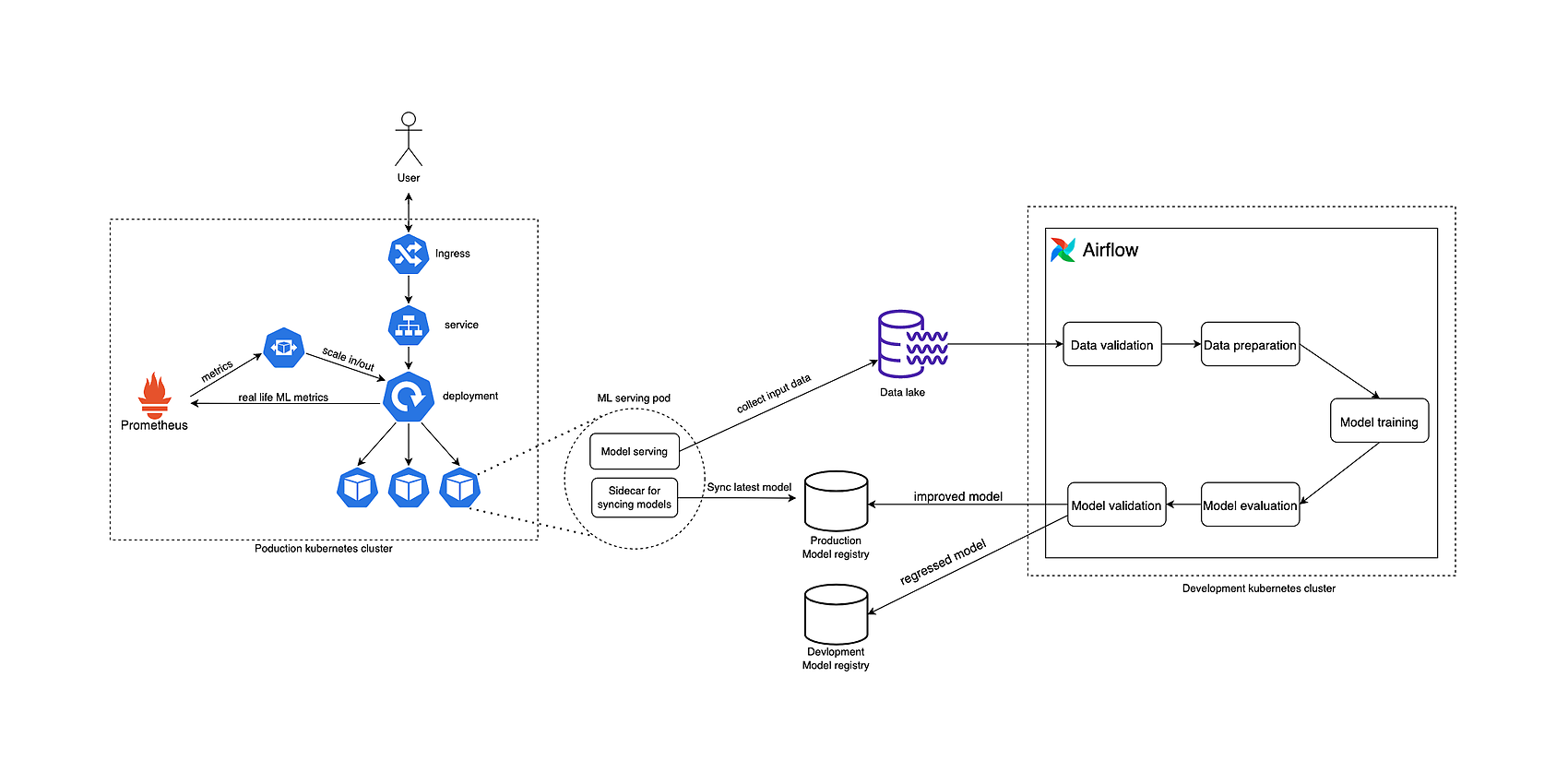
The machine learning model is shared with its customers through an API. It is encapsulated into a pod that hosts two containers: one serving the ML model and one sidecar container for syncing the latest production tagged model from the model registry. This mechanism works in a pull-based manner; the sidecar checks for a new model. It exchanges the serving model if it finds a new one, ensuring that every new production tagged ML model gets deployed automatically. The ML pods are managed by deployments, ensuring that we always have the desired number of pods running. Since the ML model is deployed as an API, its demand can be highly varying. Therefore, the number of pods needs to be dynamically scaled in and out to maintain satisfactory performance and response times. To tackle this issue, we introduced HorizontalPodAutoscaler (HPA), which dynamically changes the target pod number on the deployment object according to the specific metrics (such as the number of requests per second, CPU and memory consumption, etc.) that it receives from Prometheus. The customers of the API can reach the pods inside the Kubernetes cluster through ingress and service components. It's important to mention that the model's performance needs to be monitored, and the input data need to be persisted so a new model can be retrained user data if a concept or model drift occurs. These goals are accomplished via exporting the ML performance-related metrics to Prometheus and persisting input data to the data lake as extra training data. If there is a need for additional awareness, a Grafana dashboard can be created from the ML performance metrics persisted in Prometheus with additional alerting about the model performance.

Category: |
|
Tags: |
Machine Learning |

